Documentation
Документация
1. Opening Files (Files Tab)
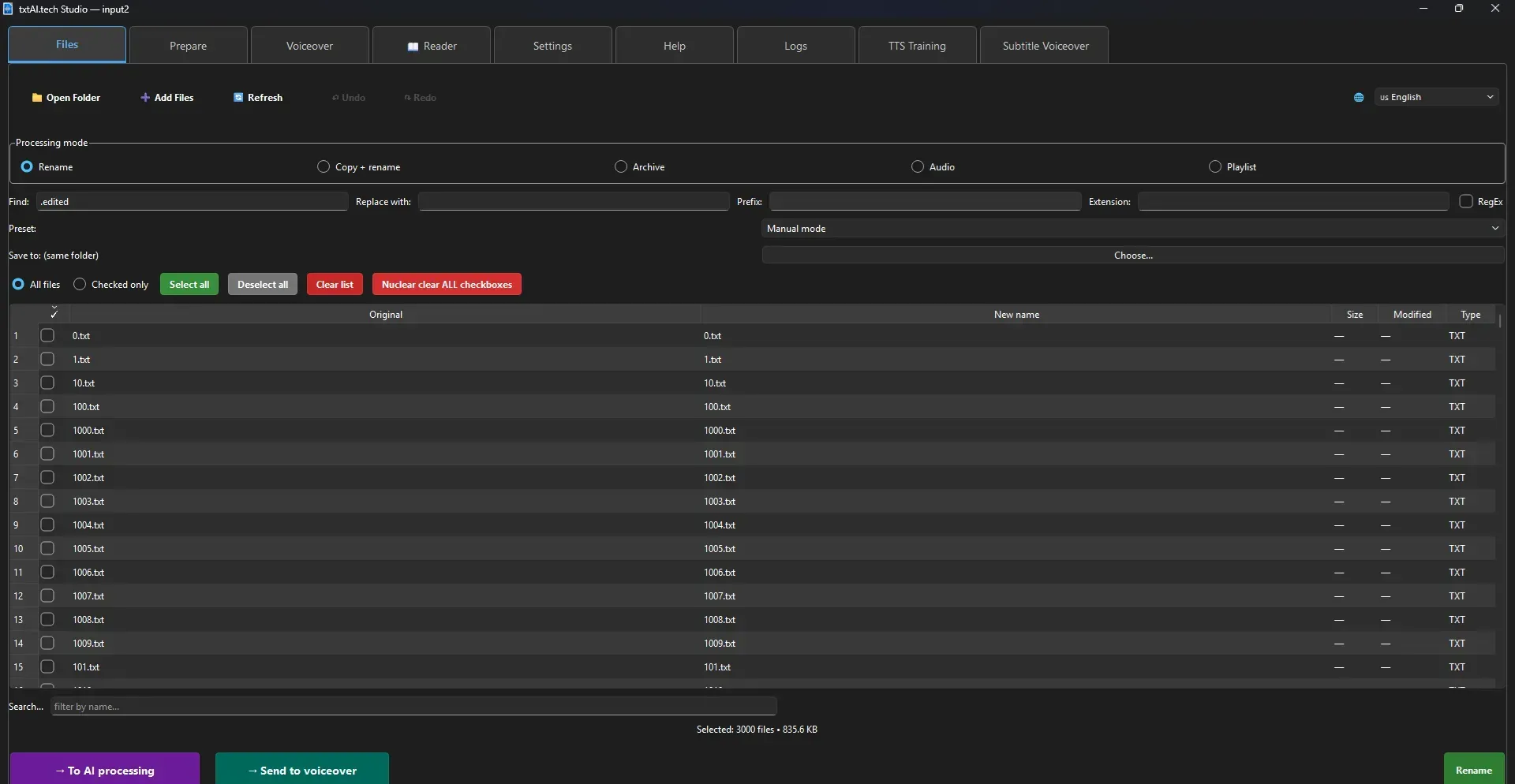
📁 Open Folder on the toolbarOption 2: Click
➕ Add Files to select individual filesOption 3: Drag & drop files/folders directly into the window
2. Renaming Files
ApplyUse
↶ Undo (Ctrl+Z) to roll back if needed.
3. Book Conversion
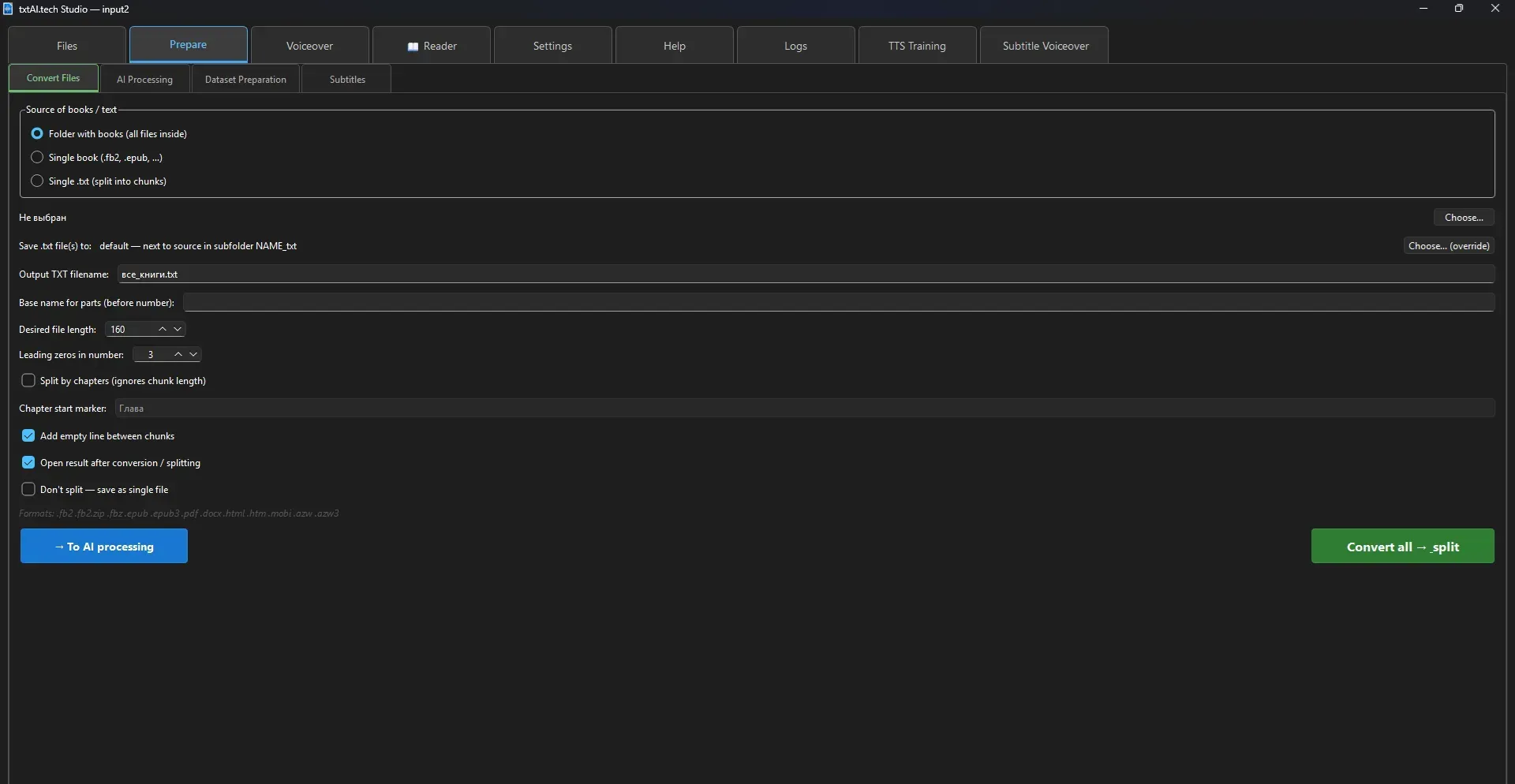
Split → TXT
4. AI Text Processing
Start Processing!
5. Text-to-Speech
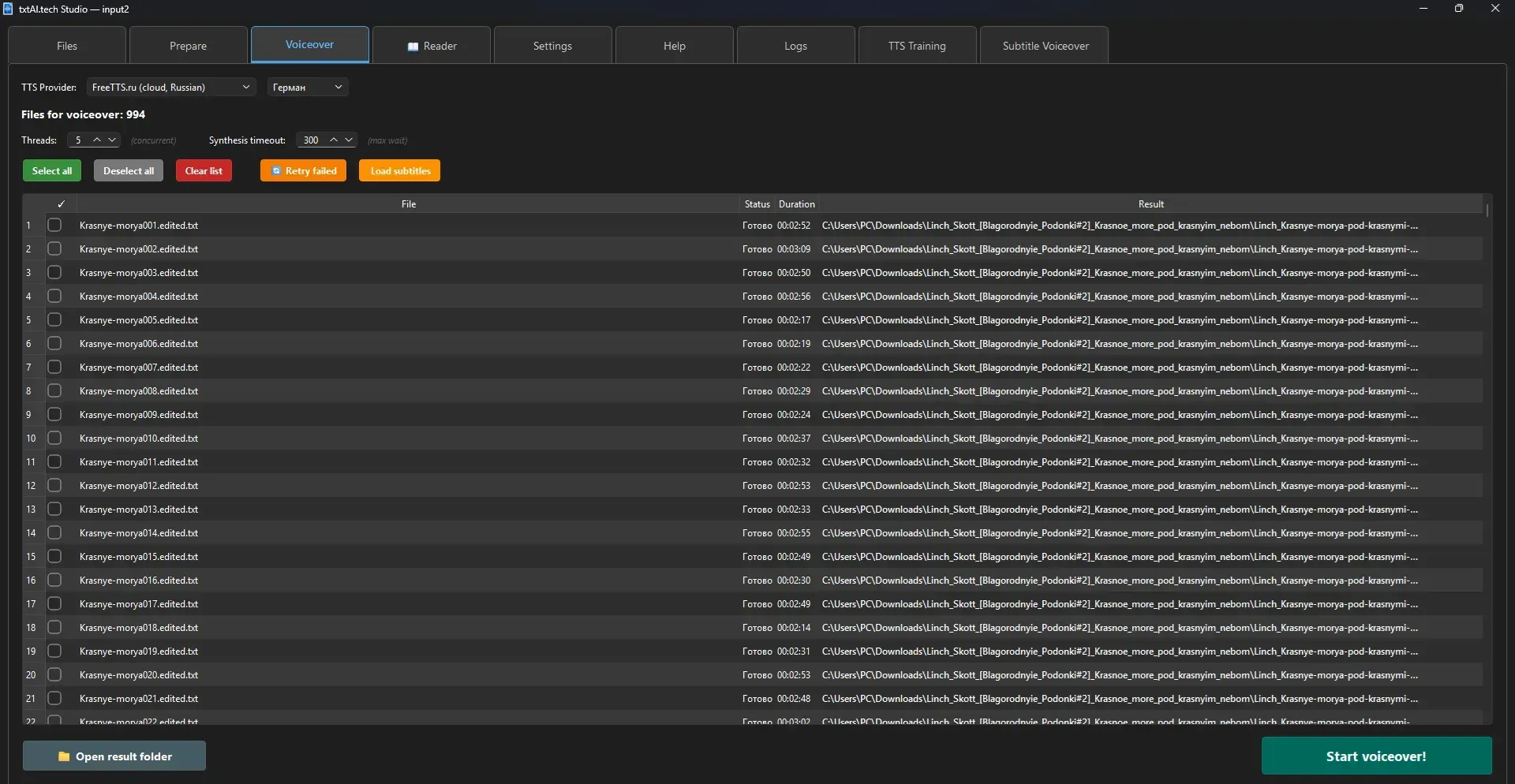
Start Voiceover!
6. Book Playback (Reader)
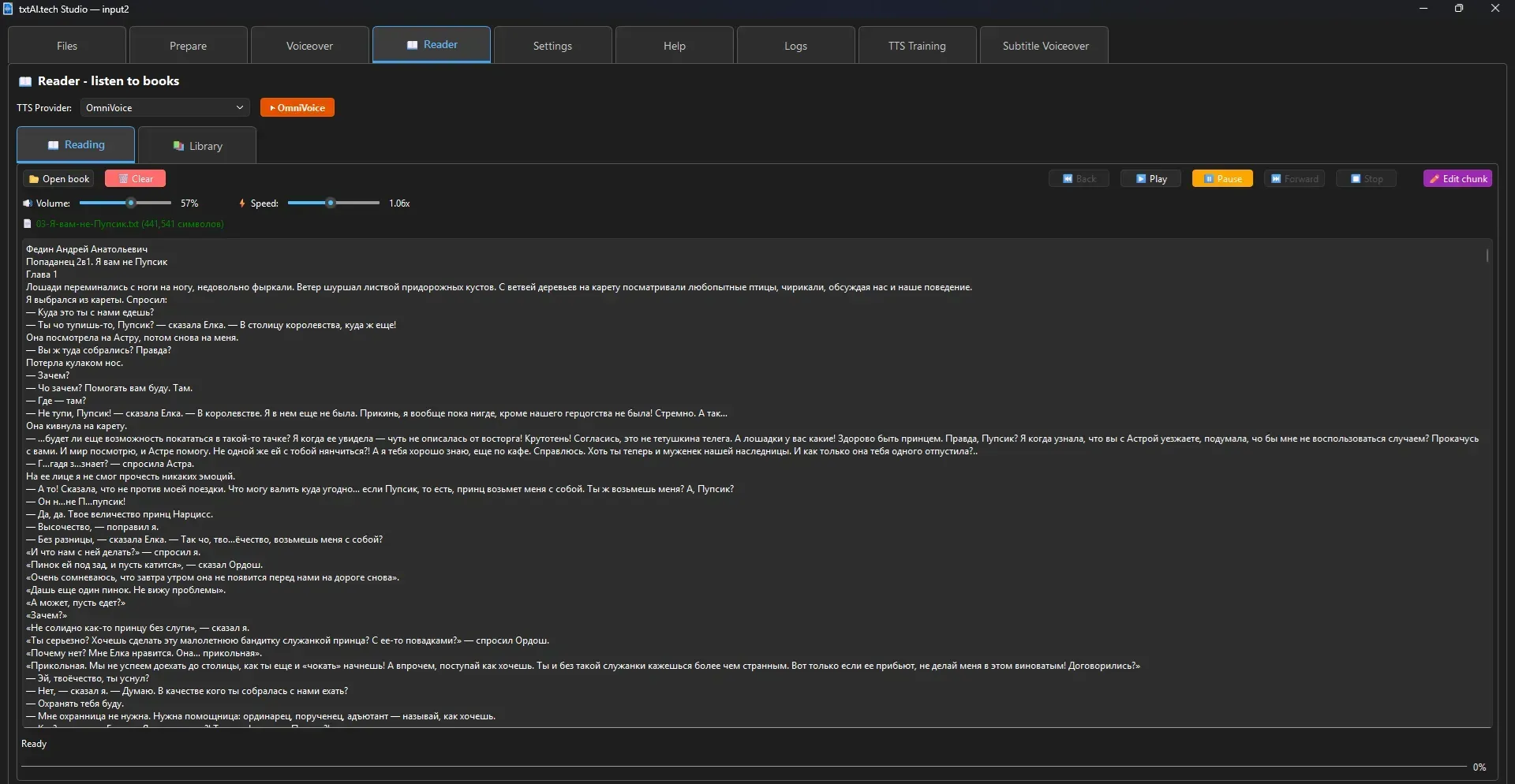
📂 Open Book → Click ▶️ Play → Use ⏸️ Pause, ⏮️ Previous, ⏭️ Next
1. Открытие файлов (вкладка Файлы)
📁 Открыть папку на панели инструментовСпособ 2: Нажмите
➕ Добавить файлы для выбора отдельных файловСпособ 3: Перетащите файлы/папки прямо в окно программы
2. Переименование файлов
ПрименитьИспользуйте
↶ Отменить (Ctrl+Z) если нужно откатить.
3. Конвертация книг
Разбить → TXT
4. Обработка текста через AI
Погнали обрабатывать!
5. Озвучка текста
Погнали озвучивать!
6. Прослушивание книг (Читалка)
📂 Открыть книгу → Нажмите ▶️ Прослушать → Используйте ⏸️ Пауза, ⏮️ Назад, ⏭️ Вперёд
🐦 Piper TTS (Local, CPU/GPU)
Fast and lightweight speech synthesis. Runs on CPU, no powerful GPU required. Port: 5003
Install Piper → 3. Wait for voice models → 4. Start with ▶ Start Piper🎙️ XTTS v2 (Local, GPU)
High-quality voice cloning. Requires NVIDIA GPU with CUDA. Port: 5002, Python 3.9–3.11, min 4 GB VRAM.
Install XTTS v2 (~3 GB) → 4. ▶ Start XTTS🗣️ Kokoro-Ruslan (Local)
Russian-language TTS based on Kokoro model. Port: 5004
Install Kokoro-Ruslan → 3. Wait for model → 4. ▶ Start Kokoro🌍 OmniVoice (Local, GPU, 646 languages)
Zero-shot multilingual TTS with voice cloning. Requires NVIDIA GPU. Port: 5005. Isolated environment (own torch 2.6 + transformers 5.x).
Install OmniVoice (~4 GB) → 3. Wait for model download → 4. ▶ Start OmniVoice☁️ FreeTTS.ru (Cloud, Free)
Free cloud service. No installation, no API key needed.
☁️ Puter.js TTS (Cloud)
Cloud TTS via Puter.js. Supports AWS Polly, OpenAI TTS, and ElevenLabs.
🐦 Piper TTS (локальный, CPU/GPU)
Быстрый и лёгкий синтез речи. Работает на CPU. Порт: 5003
Установить Piper → 3. Дождитесь загрузки моделей → 4. ▶ Запустить Piper🎙️ XTTS v2 (локальный, GPU)
Высококачественный клон голоса. Требует NVIDIA GPU с CUDA. Порт: 5002, Python 3.9–3.11, мин. 4 ГБ VRAM.
Установить XTTS v2 (~3 ГБ) → 4. ▶ Запустить XTTS🗣️ Kokoro-Ruslan (локальный)
Русскоязычный TTS на базе модели Kokoro. Порт: 5004
Установить Kokoro-Ruslan → 3. Дождитесь загрузки → 4. ▶ Запустить Kokoro🌍 OmniVoice (локальный, GPU, 646 языков)
Мультиязычный TTS с клонированием голоса. Требует NVIDIA GPU. Порт: 5005. Изолированное окружение (свой torch 2.6 + transformers 5.x).
Установить OmniVoice (~4 ГБ) → 3. Дождитесь загрузки модели → 4. ▶ Запустить OmniVoice☁️ FreeTTS.ru (облачный, бесплатный)
Бесплатный облачный сервис. Не требует установки и API-ключа.
☁️ Puter.js TTS (облачный)
Облачный TTS через Puter.js. Поддерживает AWS Polly, OpenAI TTS и ElevenLabs.
Adding Files
➕ Add Files and select TXT files, or drag & drop into the table, or transfer from Prepare tab using → To Voiceover.Processing Settings
Timeout — max response wait time (sec)
Voice — select from available voices
Speed — speech rate (if supported)
Controls
🚀 Start Voiceover! — begin for selected files⏹ Stop — stop current voiceover📂 Open Result — open folder with finished audio
Results are saved to a tts_output subfolder next to the source files (WAV or MP3).
Добавление файлов
➕ Добавить файлы и выберите TXT-файлы, или перетащите в таблицу, или передайте с вкладки Подготовка кнопкой → В озвучку.Настройки обработки
Таймаут — макс. время ожидания ответа (сек)
Голос — выбор из доступных голосов
Скорость — скорость речи (если поддерживается)
Управление
🚀 Погнали озвучивать! — запуск для выбранных файлов⏹ Стоп — остановка текущей озвучки📂 Открыть результат — открыть папку с готовыми аудио
Результаты сохраняются в подпапку tts_output рядом с исходными файлами (WAV или MP3).
Opening a Book
📂 Open Book → Select a TXT file → Text loads and splits into chunks.Playback Controls
▶️ Play — start from current position
⏸️ Pause — pause
⏹️ Stop — full stop⏮️ Previous — previous chunk
⏭️ Next — next chunk
Volume & Speed
Streaming Mode
Text is voiced on the fly — the next chunk generates while the current one plays. No need to wait for the entire book.
Library
The Reader remembers opened books. Last reading position is saved automatically. Continue from where you left off.
Открытие книги
📂 Открыть книгу → Выберите TXT-файл → Текст загрузится и разобьётся на фрагменты.Управление воспроизведением
▶️ Прослушать — начать с текущей позиции
⏸️ Пауза — приостановить
⏹️ Стоп — полная остановка⏮️ Назад — предыдущий фрагмент
⏭️ Вперёд — следующий фрагмент
Громкость и скорость
Потоковый режим
Текст озвучивается «на лету» — следующий фрагмент генерируется пока воспроизводится текущий. Не нужно ждать озвучки всей книги.
Библиотека
Читалка запоминает открытые книги. Последняя позиция чтения сохраняется автоматически. Можно продолжить с того места где остановились.
txtAI.tech Studio includes built-in prompt presets for AI text processing. You can also create your own.
Prompt Structure
Preset Categories
Minimal Edits
Fix typos, punctuation, grammar. Text stays close to original.
Literature
Literary editing, style improvement, genre adaptation.
Science & Tech
Scientific style, technical docs, simplifying complex texts.
Business
Business correspondence, marketing, presentations.
TTS-Specific
Preparing text for voiceover: pauses, abbreviations, numbers.
Subtitles
Subtitle formatting, line splitting, screen adaptation.
txtAI.tech Studio содержит встроенные пресеты промптов для обработки текста через AI. Вы также можете создавать свои.
Структура промпта
Категории пресетов
Минимальные правки
Исправление опечаток, пунктуации, грамматики. Текст максимально близок к оригиналу.
Литература
Художественная редактура, улучшение стиля, адаптация для жанров.
Наука и техника
Научный стиль, техническая документация, упрощение сложных текстов.
Бизнес
Деловая переписка, маркетинговые тексты, презентации.
TTS-специфичные
Подготовка текста для озвучки: паузы, аббревиатуры, числа.
Субтитры
Форматирование субтитров, разбиение на строки, адаптация для экрана.
📋 General
⚡ Performance
🤖 AI Models
Text Processing: Custom Server, Puter AI, LLM7.IO, g4f, OpenAI, Anthropic, Gemini.
API Keys: OpenAI, Anthropic, Google Gemini, ElevenLabs.
🌐 Network & Proxy
📦 Dependencies
📋 Общие
⚡ Производительность
🤖 Нейронки
Обработка текста: Custom Server, Puter AI, LLM7.IO, g4f, OpenAI, Anthropic, Gemini.
API-ключи: OpenAI, Anthropic, Google Gemini, ElevenLabs.
🌐 Сеть и прокси
📦 Зависимости
General
| Shortcut | Action |
|---|---|
Ctrl+Z | Undo |
Ctrl+Y | Redo |
Ctrl+O | Open folder |
Esc | Cancel operation |
Ctrl+A | Select all files |
Delete | Remove selected |
Ctrl+S | Save settings |
Drag & Drop
Prepare — drag books (EPUB, FB2, DOCX, PDF)
Voiceover — drag TXT files
Reader — drag a TXT file to open
Общие
| Клавиша | Действие |
|---|---|
Ctrl+Z | Отменить |
Ctrl+Y | Повторить |
Ctrl+O | Открыть папку |
Esc | Отменить операцию |
Ctrl+A | Выделить все файлы |
Delete | Удалить выбранные |
Ctrl+S | Сохранить настройки |
Drag & Drop
Подготовка — перетащите книги (EPUB, FB2, DOCX, PDF)
Озвучка — перетащите TXT-файлы
Читалка — перетащите TXT-файл для открытия
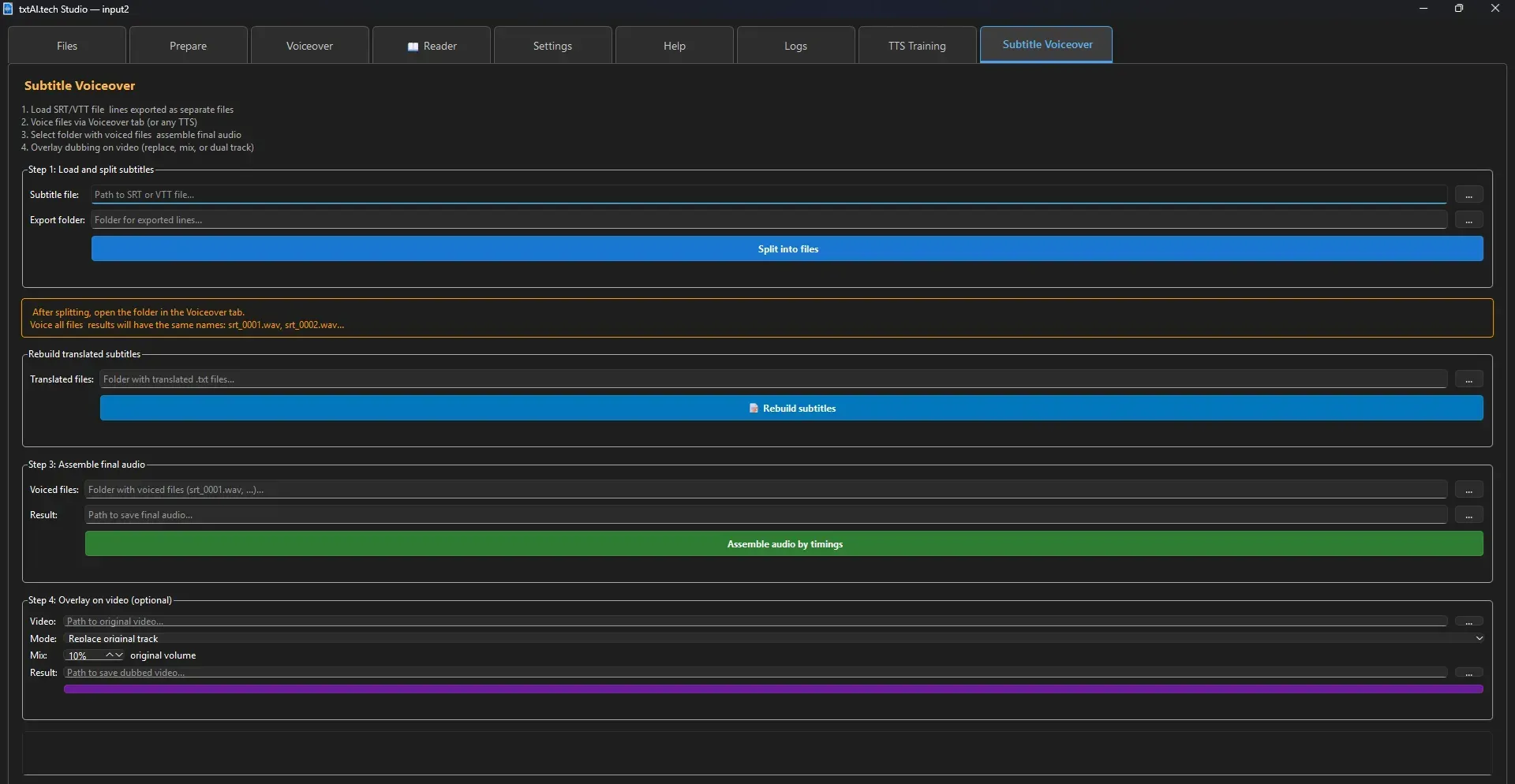
Subtitle Workflow Overview
txtAI.tech Studio provides a complete pipeline for subtitle creation, translation, voiceover and dubbing — from raw audio/video to a fully dubbed video file.
1. Generate Subtitles from Audio/Video
▶ Generate subtitlesOutputs SRT, VTT or both formats. Uses WhisperX with GPU acceleration for fast, accurate transcription.
2. Split Subtitles into Lines
📄 Split into filesEach subtitle line becomes a separate numbered .txt file:
srt_0001.txt, srt_0002.txt, etc.
3. Translate via AI
📂 Load subtitles in the AI Processing tab → Select the folder with split .txt files → Choose AI provider and translation prompt → Click Start Processing!All lines are translated in parallel. Results saved as
srt_0001.edited.txt, etc.
4. Rebuild Translated Subtitles
📝 Rebuild subtitlesCreates a new SRT/VTT file with original timings but translated text. Saved next to the original.
5. Voice the Translated Lines
📂 Load subtitles in the Voiceover tab → Select the folder with translated .txt files → Choose TTS provider → Click Start Voiceover!Each line is voiced as a separate .wav file with matching numbering.
6. Assemble Dubbed Audio
🔊 Assemble audio by timingsPlaces each voiced clip at its subtitle timestamp. Mild time-stretch via FFmpeg atempo (pitch-preserving) when needed.
7. Overlay on Video
• Replace — remove original audio, use only dubbed
• Mix — keep original at low volume + dubbed at full volume
• Dual track — both audio tracks in the video (switchable in player)
Click
🎬 Overlay on video → Done!
Обзор работы с субтитрами
txtAI.tech Studio предоставляет полный конвейер для создания субтитров, перевода, озвучки и дубляжа — от исходного аудио/видео до готового дублированного видеофайла.
1. Генерация субтитров из аудио/видео
▶ Генерировать субтитрыРезультат в формате SRT, VTT или оба. Используется WhisperX с GPU-ускорением.
2. Разбивка субтитров на строки
📄 Разбить на файлыКаждая строка субтитров становится отдельным .txt файлом:
srt_0001.txt, srt_0002.txt и т.д.
3. Перевод через AI
📂 Загрузить субтитры во вкладке Обработка нейронкой → Выберите папку с .txt файлами → Выберите AI-провайдер и промпт для перевода → Нажмите Погнали обрабатывать!Все строки переводятся параллельно. Результаты:
srt_0001.edited.txt и т.д.
4. Сборка переведённых субтитров
📝 Собрать субтитрыСоздаётся новый SRT/VTT файл с оригинальными таймингами, но переведённым текстом. Сохраняется рядом с оригиналом.
5. Озвучка переведённых строк
📂 Загрузить субтитры во вкладке Озвучка → Выберите папку с переведёнными .txt файлами → Выберите TTS-провайдер → Нажмите Погнали озвучивать!Каждая строка озвучивается в отдельный .wav файл с соответствующей нумерацией.
6. Сборка дубляжа
🔊 Собрать аудио по таймингамКаждый клип размещается по временной метке субтитра. При необходимости применяется мягкое ускорение через FFmpeg atempo (без изменения тона).
7. Наложение на видео
• Заменить — удалить оригинальную дорожку, оставить только дубляж
• Микшировать — оригинал тихо + дубляж на полной громкости
• Две дорожки — обе аудиодорожки в видео (переключаются в плеере)
Нажмите
🎬 Наложить на видео → Готово!